hpdz.net
High-Precision Deep Zoom
Fractal Animations and Images
Click here to subscribe to the HPDZ.NET newsletter
What's New
A modestly deep zoom into the Cubic Burning Ship fractal. With 25X oversampling, this video is crisp and clean and shows some new features in this starkly beautiful, gorgeous fractal.
 |  |  |  |
 |  |  |  |
 |  |  |  |
Mission
This site is the web presence of a project dedicated to producing high-precision deep-zoom animations and still images of the Mandelbrot set and other fractals, and to advocating mathematics and computer programming, which are at the core of how these works are created.
This project lives by two guiding principles:
Letting the shapes speak for themselves
Citius, Profundius, Fortius
The first statement means that fidelity to the structure of the fractal is the most important artistic consideration here. This is not art that happens to have a fractal in it; this is an art dedicated to showing as accurately as possible how the fractals truly look.
The second statement inspires the technical side of this work. Rather than striving for Altius, we strive for Profundius.
What do "High-Precision" and "Deep-Zoom" mean?
These images are high-precision because they zoom in way beyond the standard precision of most computers, to magnifications of 1030, 1050, or even to 10120! That's so big that a if a subatomic particle were magnified that much, it would be larger than the universe! Doing this requires special software to handle that extra math, and that is a technical challenge every bit as demanding as the artistic challenges of finding great images.
These animations are also "high-precision" in a different sense -- the images and videos are very high-quality, carefully crafted and beautifully colorized fractal images rendered with precise fidelity to the original underlying fractal structures.
What's a fractal? What are these videos all about?
A fractal is a type of mathematical object with a very complex structure, with infinite detail at all size scales. Some fractals are simply regular repetitions of a single pattern, while others have complicated, intricate shapes.
Most of the the videos here are deep-zoom animations into a particular fractal known as the Mandelbrot set, starting off with an overview of the set, then magnifying billions, trillions, and far far more. Fractals have exquisite detail at all levels of magnification, infinitely great detail, in fact, so there is always something more to see, no matter how much has been explored before. The structures in the Mandelbrot set and other fractals at these extreme levels of magnification can be truly spectacular, unlike anything ever seen before.
A quick explanation of how the images and videos are created is below in the introduction to the Technical section. The pages in the Technical section of this site have far more detail on different topics related to creating fractal images and animations.
Animations
Some of the best deep-zoom fractal animations ever made are here. Most of the animations are deep-zooms into the Mandelbrot set, but some feature rather unusual fractals not seen anywhere else.
Magnet Fractal | Burning Ship Fractal | Burning Ship Deep-Zoom Animation |
Here's a quick overview of the gallery of Mandelbrot set deep-zooms. Visit the Animations main page for more details, or click on an image in the table below to go the the page for a particular video.
GroupB | Take5 | Project17 | |
Canyon2 | Metaphase Variation 1 | Canyon1 | HD1 "Tartaglia" |
DEHP-III "Cardano" | Ununennius "De Moivre" | Rift | Metaphase |
Prima Luce | Project X | Tevaris | DEHP-IIa |
The Mandelbrot set is a rich source of great art, and it is particularly nice for making videos because the equation that generates it is fairly simple and doesn't take much computational power. But many more fractals have been discovered, and quite a few of them are great for creating deep-zoom animations. One of the simplest variations on the regular Mandelbrot set fractal is the cubic Mandelbrot set, and here you will find two animations into that fractal, one of which (QBIX) is the deepest zoom into the cubic Mandelbrot set ever created.
QBIX | ThirdOrder |
Deep zooms are not the only type of fractal animation. Another way of making great fractal videos is to change some part of the equation that specifies the shape of the fractal. This creates a morphing type of effect where the fractal changes shape as the video progresses. Two videos of this type have been pubslished here so far. These videos are unique because they use a new fractal formula developed here and never before used for animations, the Secant Method.
Secant Animation 1 | Secant Animation 2 |
Technical Animations
This site is dedicated not only to producing great art, but also to promoting the underlying technical elements that make it possible. Some short animations demonstrating various technical points have been published here too. Some of these are also celebrating important milestones in the development of the software.
PanTest2-HD | Circle | ZeroOne | HiPrecPanTest |
PanTest2 | How Not To Zoom | Interpolation BL vs NN | Rank-Order Demo |
These two videos were originally put in the Animations gallery, and unlike the other "technical" animations, each one has its own special page. They are both very nice to look at and have great coloring and nice music, but really, they are just technical demonstrations of deep zooming to beyond 10100 magnification.
E100 | Centanimus |
Still Images
Animations are great, but you can't hang one on your wall, and the resolution is necessarily limited by video playback speeds and the practical realities of rendering thousands of frames to make a video. Sometimes a great still image is an accomplishment all by itself.
A nice collection of fractal still images is available here, including many images of fractals other than the Mandelbrot set.
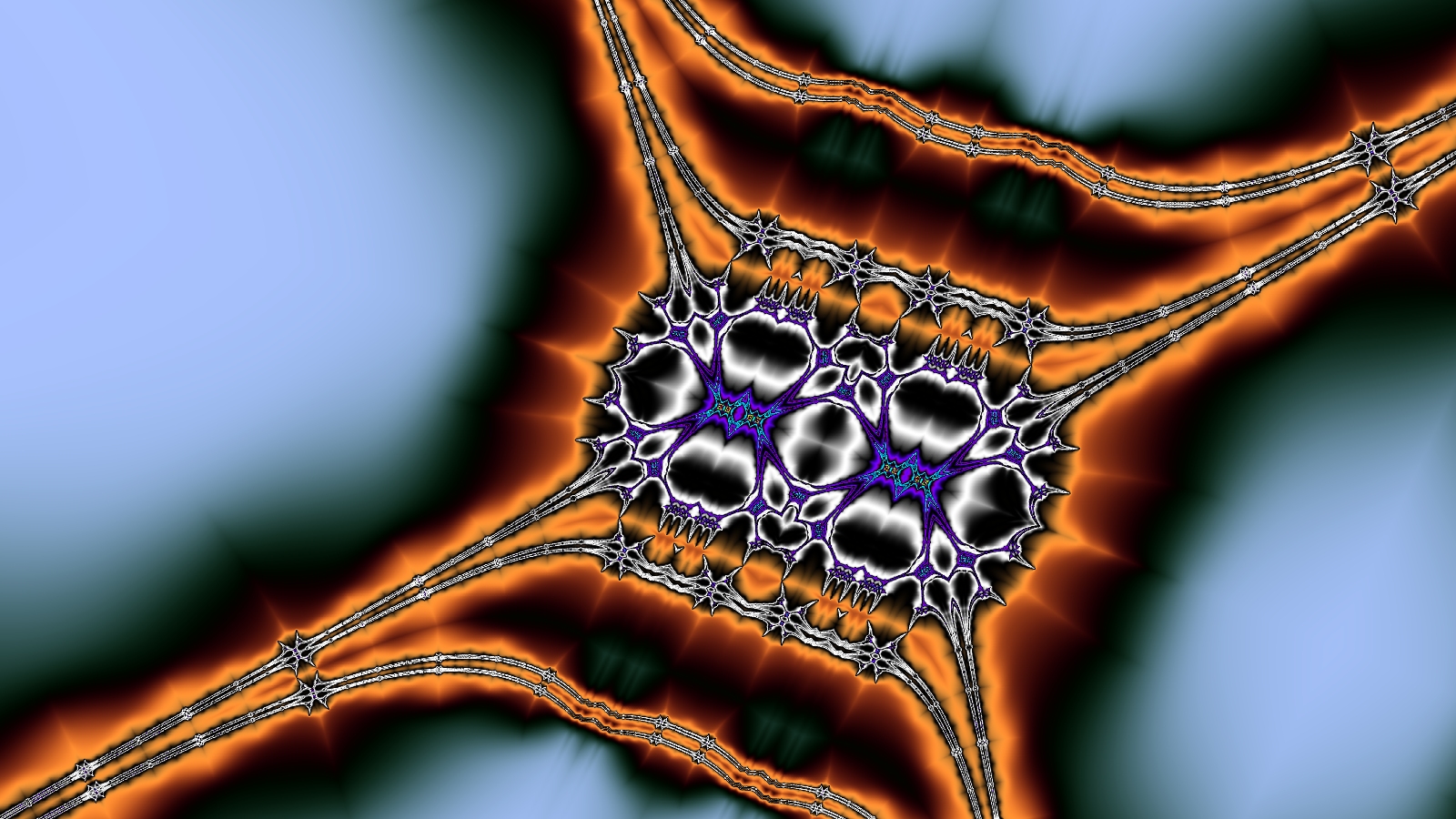
 Secant Butterfly Third Place! |  Secant Cosine |  Four Kisses |
 |  | 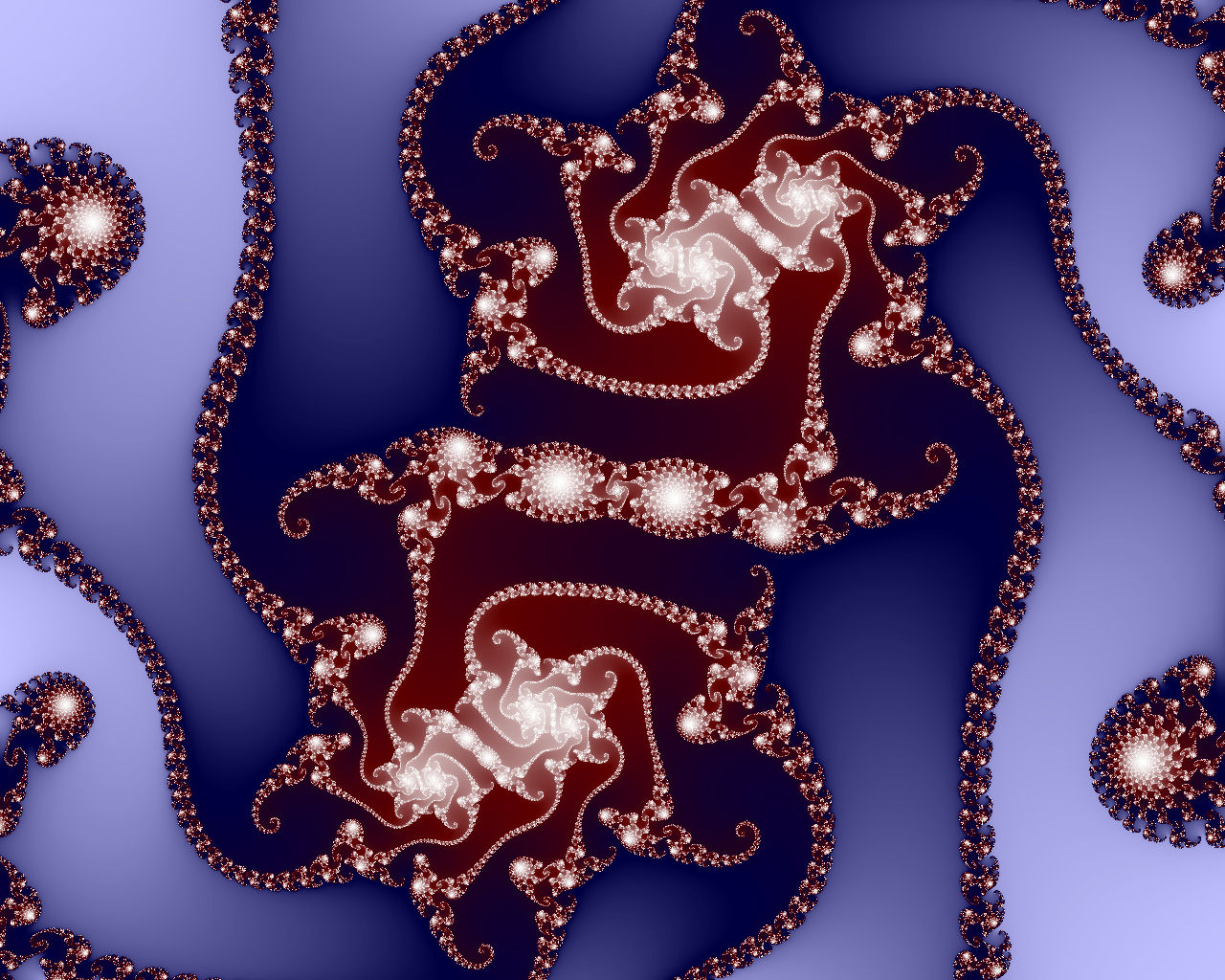 |  |
 |  |  |  |
 |  |  |  |
 |  |  |  |
 |  |  |  |
Other Fractals
Many types of fractals besides the Mandelbrot set have been invented. Some of them make good deep zoom images, while others don't look different when magnified.
Secant Method Fractals are an innovation unique to HPDZ.NET. The secant method is similar to Newton's method for solving equations, but converges more slowly to the solution. That slower convergence results in much more complex and interesting fractal structures than Newton's method gives. This is a rich source of amazing images. Two animations are published on here that are based on the secant method.
 |  |  |  |
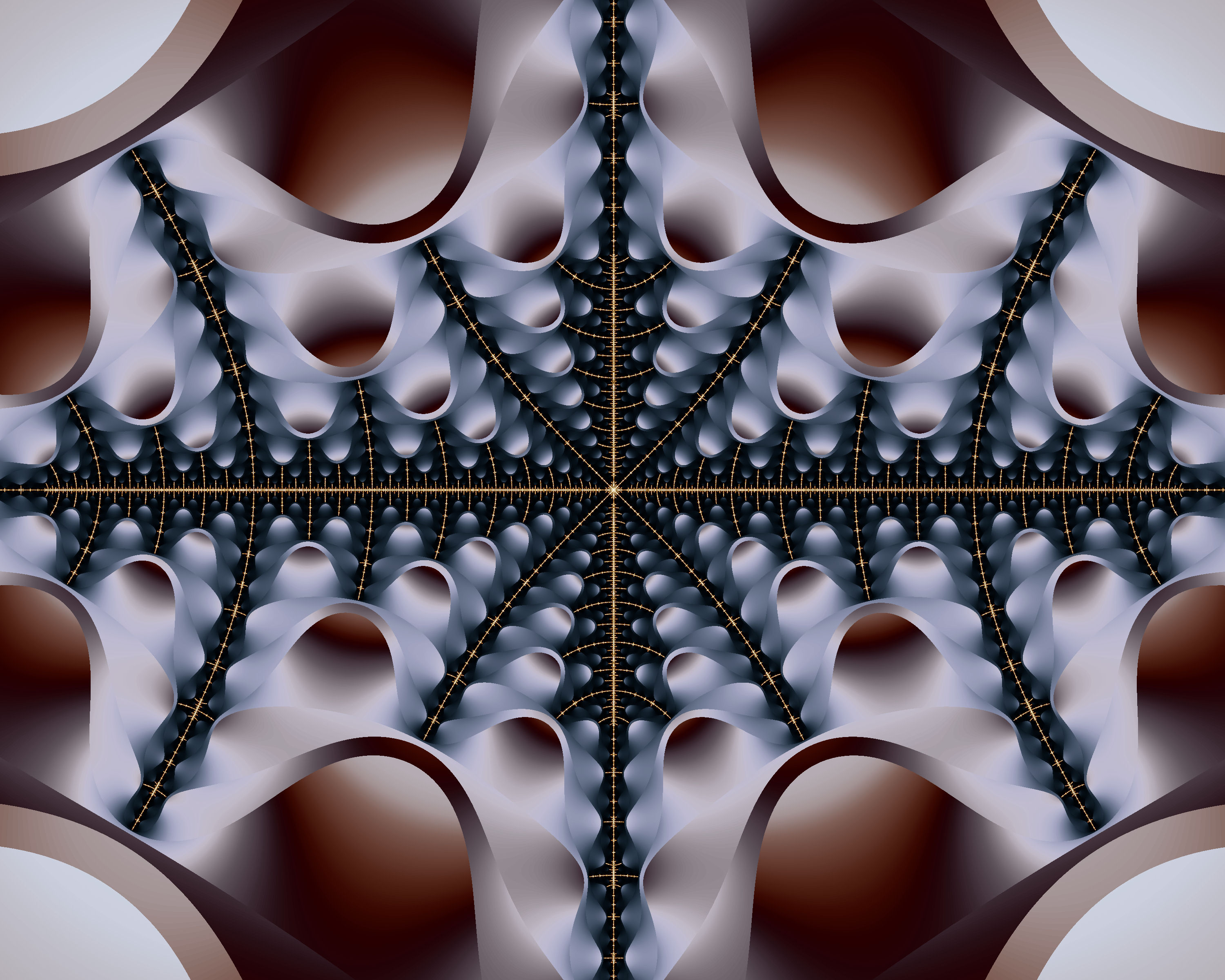
Newton's method and Halley's method are techniques for estimating numerical solutions to equations based on successively refining guesses at the solution. They are iterative procedures just like the process for generating the Mandelbrot set, and they make some nice fractals. Depending on which function is used, many different images result, but they are all very self-similar and don't new structure with deep zooming.
Cube roots of 1  | Zeros of the sine function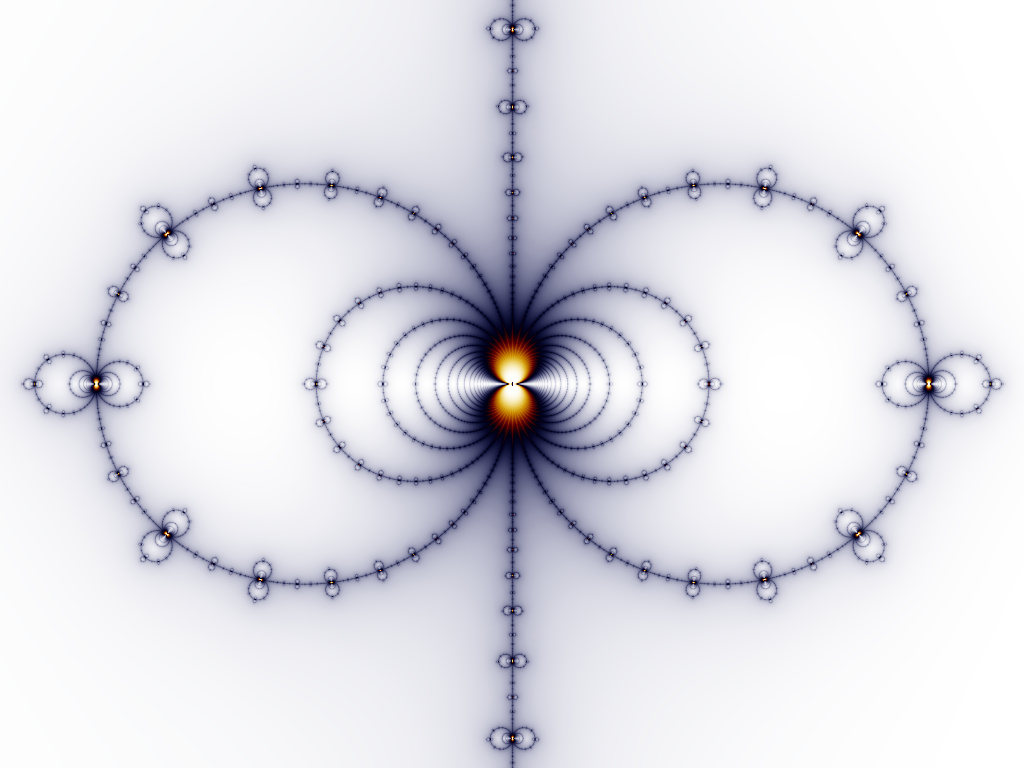  | Tenth roots of 1 |
 |  |
The Nova Fractal is related to Newton's method. It has a lot of structure at higher magnifications and produces nice deep zoom images. A bug in the first attempt to render this fractal on this site created a new variation on the Nova fractal, which is the last image on the right below.
 |  |  |  |
The "Bat" Fractal resulted from a bug in the software while developing the Nova rendering.
 |  |  |  |
The Henon Map Fractal (Phoenix Fractal) results from iterating the Henon map, which is a second-order polynomial that includes a term from one time step back, so it's more complicated than the usual Mandelbrot set. This fractal has a whole page devoted to it on this site, and there are two short demo videos on the Demos page.
 |  |  |  |
Magnet Fractals are based on some equations from theoretical physics that describe how certain magnetic materials behave.
Type 1  | Type 2  |
Technical Information
In addition to advocating the artistic aspect of fractals, this site seeks to be a resource for anyone interested in math and computers. A large technical section discusses the details of how the images and videos are created, from the nuts-and-bolts of the high-precision arithmetic to the details of colorizing fractals, and even to practical issues like how to manage an email newsletter.
- General information
- Software issues
- Video production and web site information
How are these images and videos created?
Each type of fractal corresponds to a particular mathematical function that is applied to each point in an image. The result of that function is fed back into the function again, and again, over and over. As this process is iterated, sometimes the output of the function will grow larger and larger, diverging to infinity (imagine for example doing this with x2, starting with x>1). Sometimes, the output will converge to a particular value (again, imagine doing this with x2, but this time starting with x<1). And sometimes the output will settle into a cycle between several different numbers. For some functions, some starting values even give a series of numbers that is randomly jumping around all over the place. The colors in the images reflect what each function is doing and how quickly it settles into that behavior.
For more details, see the Math page in the technical section.
A closing thought
"NO, PLEASE! Not deep-zooms!!! I don't want to tie up my computer with those - generally boring - images, and I don't want to download them (my phone bill is already way too high...)."
-- FractInt Digest 29 Mar 1998 (author unknown)
This site uses no Java and no Flash and has NO ads! -- no trojans here!
All content Copyright by Michael Condron. All rights reserved unless otherwise noted.
You may download, save, and print a single copy for personal use only.
Music by various sources used with permission.
Please refer to individual video file credits for details.
