hpdz.net
High-Precision Deep Zoom
Technical Info - Animation
Introduction
For the most part, animation is pretty simple -- you just make a bunch of images and hook them together into a video. If all you're doing is zooming into a fixed point at a steady rate, there is probably not much to talk about. But there are some technical complications that deserve some discussion for achieving more sophisticated effects. And of course there's the whole frame interpolation business....
Topics on this page
Zooming and Panning
Animation paths are calculated using an exponential function to provide zooming. A polynomial function provides smooth starting and stopping. Similarly, a polynomial function scaled to the frame size controls panning.
Simultaneous panning and zooming is harder than it seems at first glance. This is implemented with a complicated scale-invariant panning adjustment so panning is well-behaved even while zooming (see HowNotToZoom for an example of what motivated me to develop this). The mathematical details are really tedious, so I'm not going to go into it here. If anyone is interested I can provide more information.
Colorizing Animations
Colorizing animations poses some challenges that are not evident when colorizing still images. We can take two basic approaches to mapping colors in animations, described in the following sections.
Static Mapping
Static mapping defines a single mapping from counts to colors, and that map is used throughout the entire animation. All the animations on this site created prior to July 2008 use some type of static mapping, typically a linear map with a high period number. This can work fairly well in some cases, but most of the time results in sections of the video that are either nearly all one color or are too busy, with the color palette repeated dozens of times, making a noisy mess. The deeper a zoom goes, the more likely there is to be such a huge difference between the starting frames and the ending frames that a static map won't work.
Dynamic Mapping
Animations consist of a large number of still images that have quite different fractal count data. Some sections of a video may have frames with relatively low average count numbers and a small range of counts, while other sections may be zooming in near a mini-brot, which will cause a huge increase in the average count number and in the range of counts spanned by the fractal data. If we want to keep a uniform appearance of the fractal as an animation progresses, we have to find ways to dynamically adjust the parameters of the colorizing map based on the data in each individual frame.
Any mapping can be dynamically adjusted to fit each individual video frame's data. Even the simple linear map can be dynamically adjusted frame-by-frame using the minimum and maximum count numbers in each video frame. The more sophisticated methods such as rank-order and histogram mapping can adjust to the changing fractal data even better.
Some videos on this site that were made with dynamic color mapping are:
Dynamic mapping works well but presents two challenges:
- Noise in the parameters derived from the fractal count data
- Color "rolling" and "lurching"
The first issue causes the color mapping to jitter slightly from frame to frame, and is due to the fact that the fractal data is quite noisy from frame to frame, especially in the higher range of the count distribution. The second issue, color rolling, is caused by the range of counts expanding and contracting as the animation progresses. When the rolling is really fast, I call it "lurching" since the colors seem to suddenly jump from one configuration to another.
The following graph of the count distribution from Canyon2 illustrates these effects. This shows the minimum, maximum, and median count values as a function of the frame number in the animation. This animation was rendered with the count limit set to 100K, so no count number can exceed 100K.
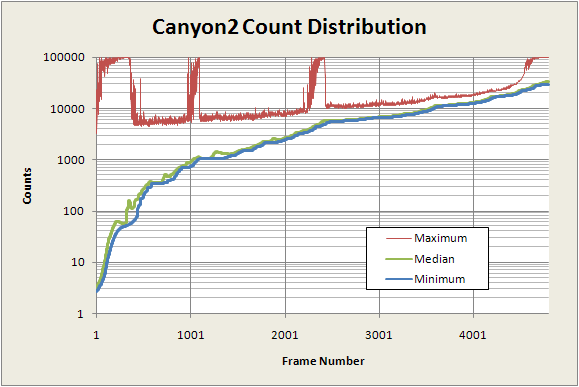
The high-frequency jitter in the data is clear, even on this coarse time scale view. Unless this is filtered or trimmed out somehow, it will cause the color map to be unstable and have annoying jitter. This effect can be seen in this example of a rank-order colored animation. In practice, we would not scale a color map using the actual maximum and minimum count numbers that we've plotted here because they are far too noisy. This graph is just to show the problem in its most impressive form.
We can also see the cause of the color rolling effect. Near the beginning, the count range is very large as we zoom in to the canyon part of the main set, then it quickly falls and remains steay, but later two additional large peaks in the maximum count appear as mini-brots dominate the image and then leave. Meanwhile, the minimum count slowly and steadily rises. As the range of counts expands and contracts, the same set of colors has to serve a very different set of count data.
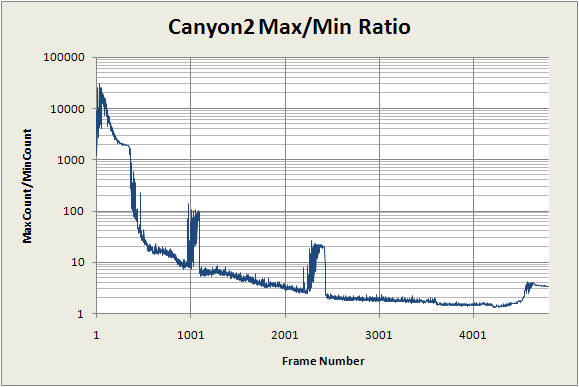
The variation in range of counts is enormous, as seen in the following graph of the maximum count divided by the minimum count. At the beginning, the ratio is about 10,000, while near the end it is as small as 1.5, then rises to about 3 in the very last few seconds.
Here is a video demonstrating how the distribution of counts moves and changes as this animation progresses. This was made by binning the count data for each frame into only 500 bins, so it doesn't show as much detail as the graphs above, but it gets the main point across.
Canyon2 was colorized using a very elaborate set of filters to smooth the scaling data over time. This system uses a large amount of information from the distribution of the counts at every frame, not just the minimum and maximum, to develop a time-varying color map that attempts to find the best compromise between the needs of all the video frames. The detailed mathematics of this is more than I can describe in a text-based web page, and this is still a work in progress.
Rank Order or Histogram?
Many animations I've done have used local (i.e. frame-by-frame) rank-order color mapping because it is better than any of the parametric (linear, root, log) techniques at balancing colors and adapting to the changing count data as an animation progresses. But I am revisiting the use of the histogram map (thanks to encouragement from DuncanC on FractalForums.com). Here are two videos showing some early comparison results (each is a 30 MB MP4 file encoded with FastStart, so it should play when you click on it).
 |
 |
| Histo | Rank |
Note
What we are looking for here are the two effects listed above, jitter and rolling. These are MPEG-4 compressed videos, so there are some compression artifacts like blocking, but please try to ignore that.
As expected, the histogram method has much less jitter. It has a very low rate of change of color map value with respect to count number at high counts. The price we pay for that is less detail visible at high count numbers. Both approaches seem to have about the same amount of rolling and lurching.
A far superior approach is to use a globally optimized color palette. Most of the animations published here since 2010 use this technique. More on that some other time.
Frame Interpolation
Introduction
This is, in my opinion, a controversial technique for speeding up drawing of extreme deep zooms. First let me explain what it is and how it works, then why I think it is controversial. I will also explain how it can be done in a way that isn't "cheating."
Aside from the question of whether it is cheating or not, this technique involves a lot of very interesting mathematical issues from digital signal processing. Most of these issues are covered on the page on anti-aliasing.
Background
Drawing every frame in an animation individually is extraordinarily time-consuming -- it can easily take 5 minutes to draw a single 640x480 frame at modest zoom levels, and at extreme magnifications it can take hours or even days. It is also very inefficient since there is a lot of redundant information from one frame to the next. This is especially true when panning without zooming -- you're essentially recalculating 99% of exactly the same image information as in the previous frame at each step.
Frame interpolation is a way to speed this up. The idea is to draw an area once, then zoom in or pan around in that area using standard digital image processing methods to interpolate between the pixels in the larger image. Interpolating the pixels for the video frames from the larger image is much faster than drawing them all from scratch for every frame, especially for images with a very high average iteration count. For example, if you want a 320x240 video frame, you can draw, say, a 640x480 master image (sometimes called a "key frame"), hold it in memory, and zoom in to that image digitally by interpolating between the pixels in the calculated 640x480 image to generate each video frame, rather than calculating every single video output frame directly.
Frame interpolation opens areas of the set that would otherwise be prohibitively intense computationally for serious (E100-level) deep zooming, like the cusps and the Seahorse Valley. It also makes feasible ultra-deep zooms, like to E1000. But it has to be done right or the result will be cheating at the very least, or junk at the very worst.
Is This Cheating?
The pragmatist in me loves this, since it can substantially cut the time required to render a video -- by a factor of 10 or even 100, depending on how the interpolation is configured. But the purist in me balks at this. Yes, I balk. It somehow seems like cheating. Now, there are different ways of doing this, and some seem to me less like cheating than others.
The criterion I would suggest for having this not be cheating is based on the results described in the page on anti-aliasing. There are several ways to state the same concept:
- The pixel increment size, dx or dy, in any video frame should be no smaller than the pixel increment in the calculated image
- The spatial sampling rate of the video frame should be no smaller than the spatial sample rate of the calculated image
- The spatial frequency of the video frames should be no higher than that of the master image.
- If the calculated frame is MxN pixels, the video output frames should never be more than MxN pixels.
Although these criteria do not satisfy the Nyquist criteria (the factor of 2 is missing) it seems to me that they are fair. Especially when you think of item (4) -- if you have more pixels in your calculated frame than in your video frame, you're not creating information that wasn't calculated.
Who Cares?
This is important because some people claim (or at least think) the software they are using is much faster or better than other software, and some people are shocked to learn it takes weeks or months to make some animations. Maybe it's all about bragging rights, but there's also an element of basic honesty about what the capabilities of various tools are, and it's important to compare things under similar conditions.
I have seen a few staggeringly deep zooms on the internet (like E300 to E1000) and I strongly suspect they were done this way -- probably they were rendered originally at a very low resolution like 80x60, then resampled up to a higher resolution like 640x480 with pixel interpolation. This is unambiguously cheating as far as I'm concerned, if the final product is described as having a higher resolution than the underlying information justifies. I may do this kind of things for rough drafts or experiments, but not for production videos. It reminds me of the disappointingly common problem of television video formatted to 16:9 and advertized as "High-Def" but broadcast at abysmally low bit rates.
At any rate, any video that I create with frame interpolation will be clearly labeled as such.
Temporal Blending
Interpolating into individual calculated key frames results in an odd jerky effect each time the animation switches to a new large key frame. You can clearly see this in Tevaris, which was created before I had incorporated temporal blending. The solution is to overlap the interpolated video frames from each key frame by smoothly blending them as a new key frame is used. If a video frame is 70% of the way from the preceding key frame to the next key frame, then its pixels are a weighted average comprised of 30% of the key frame before it and 70% of the key frame after it.
Pixel Interpolation Techniques
Obtaining the final interpolated value of a pixel from a higher-resolution image can be done in several ways. This is a very complicated and mathematically cumbersome topic, but it deserves at least a brief mention. A comparison of the first two methods, nearest-neighbor and bilinear interpolation, is here.
This is by no means a comprehensive list of methods for resizing images, but these are the three methods that are implemented in the software that makes the videos on this site.
Whichever method is used, the interpolation is always done on the fractal count data -- not on the colorized images. Interpolation in any color space is more complicated and artifact-prone than interpolation on the raw fractal data. Colorizing is always done last in the video production process here.
Nearest Neighbor
This method simply assigns each pixel in the interpolated image the value of the primary image pixel that is closest. This is extremely fast, since it requires no calculation aside from finding the nearest neighbor, but it generates a lot of visual artifacts in the final interpolated image, the most prominent one being that the pixel sizes seem to grow and suddently shrink. It's good for quick-and-dirty resizing, but for this kind of work it doesn't have much use, since the calculation time to generate the primary data usually hundreds or thousands of times more than the time to do the interpolation to make the output video frames.
Bilinear Interpolation
This is a simple interpolation in two dimensions using the values of the pixels on the four corners of the box that contains the output pixel. A linear interpolation is done in one direction, then in the other direction; the final interpolation function is actually a quadratic function of the values at the four corners. This significantly reduces the artifacts of the nearest-neighbor method. When upsizing images (i.e. interpolating from a low-resolution image to make a high-resolution image) this method introduces some other types of noticeable artifacts, the most prominent of which are due to the discontinuity of the slopes at the boundaries between pixels. These are not quite as big a problem when downsizing, but there are more sophisticated ways of interpolating that are even better. This method does not do much to low-pass filter the input data to comply with the Nyquist criterion, so there is essentially no anti-aliasing.
Weighted Average
The method used for most interpolated animations on this site doesn't really have a name that I'm aware of. The procedure is conceptually simple, and it has some advantages. The value of the output pixel is the weighted average of the all the primary pixels that overlap the box covered by the output pixel, with the weight being the fraction of the area of the primary pixel covered by the output pixel box. This is a very time-consuming calculation, but for downsampling images, it makes use of more information from the primary image than the bilinear interpolation method (up to 9 pixels, if the downsizing is limited to 2X), and introduces some element of anti-aliasing. This is the "anti-aliasing" technique described by Peitgen in Peitgen & Saupe, The Science of Fractal Images, pp 215-218.
More sophisticated methods exist, but from a practical standpoint, are probably not necessary. The fractal count data is usually so intrinsically noisy that refining the interpolation algorithm will probably not be noticeable. The artifacts introduced by the Bilinear and Average methods just get lost in the noise from the fractal data most of the time, so using more sophisticated interpolation methods is probably not worth the effort unless the primary image has been heavily noise-reduced by oversampling.
Parameter Animations
Parameter animations are animations where some parameters of the fractal are changed with time, rather than just changing the position and magnification. This is an area with a lot of artistic potential, and many other fractal animators have made some great stuff.
There is no obvious way to do frame interpolation on this kind of animation. It causes the fundamental shape of the fractal to change with time, which is quite different than just magnifying or panning. It is probably possible to apply some of the same kind of motion prediction technology that underlies modern video compression algorithms like MPEG4 to this problem, but that is beyond the scope of anything I'm likely to be able to do any time in the foreseeable future.
All content Copyright by Michael Condron. All rights reserved unless otherwise noted.
You may download, save, and print a single copy for personal use only.
Music by various sources used with permission.
Please refer to individual video file credits for details.
